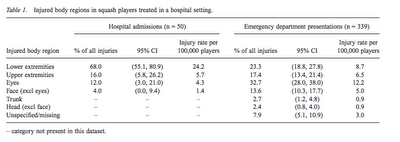
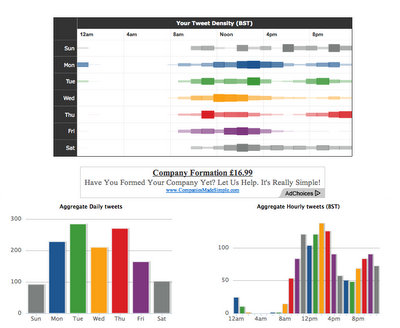
Why are we still paying for statistical software?
' What programme should I use to analyse this data? ' About ten years ago there was little choice and expensive software would have arrived in a box containing a CD-ROM! I still have SPSS and MATLAB in my applications folder. They don't come on CDs anymore, but from a central university server. Like CDs however, these programmes are on the verge of becoming a redundant medium. Given the choice of free tools available today, how are commercial alternatives going to survive? IBM acquired SPSS a few years back for $1.2 billion, which I am not convinced was a particularly smart move. Psychologists typically want to test predictions, visualise data and produce models. That said, additional functionality can often be required quickly and unexpectedly as a research project or idea develops. An open-source community allows for flexibility that paid alternatives do not offer (yet). The ba...